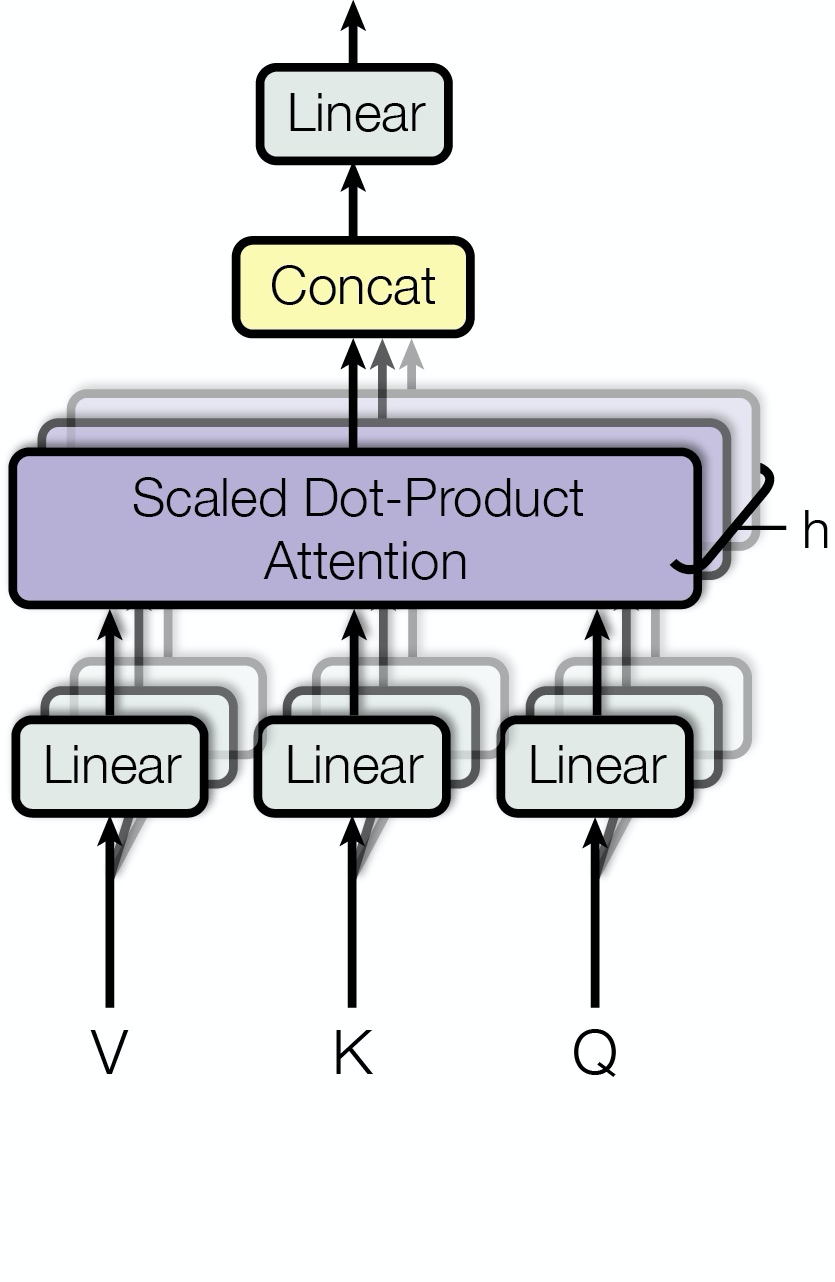
Multi-Head Attention
DONE BERT 可解释性-从”头”说起 - 知乎 [[BERT]],不停的 mask 结构,判断对指标的影响。[[2021/06/16]]
任务:query-title
按 query-doc 相关程度分成 5 类
用 BERT 做多分类
研究各个头对模型的影响:通过将 attention = 0 来 mask 对应的头
- 12 层,每层 12 个 head,共 144 个 head
结论
attention-head 很冗余/鲁棒,去掉 20%的 head 模型不受影响
144 个 head 随机 mask
分成 0-5 层、6-11 层 mask
- 底层特征对分类比较重要
各层 transformer 之间不是串行关系,去掉一整层 attention-head 对下层影响不大
各个 head 有固定的功能
某些 head 负责分词
某些 head 提取语序关系
某些 head 负责提取 query-title 之间 term 匹配关系
[[香侬科技@为什么Transformer 需要进行 Multi-head Attention?]]
借鉴了CNN中同一卷积层内使用多个卷积核的思想
Transformer,或Bert的特定层是有独特的功能的,底层更偏向于关注语法,顶层更偏向于关注语义。
多头中多数的关注模式是一致的
- 不同的关注模式由初始化带来
就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。
利用多组 $$W$$ 值和 $$X$$ 相乘,得到多组不同的 $$Q$$ $$K$$ $$V$$,分别利用这几组向量去做 self-attenttion,最终将得到的 attention 结果 concat 在一起。
$$\begin{aligned} \text { MultiHead }(Q, K, V) &=\text { Concat }\left(\text { head }{1}, \ldots, \text { head }{\mathrm{h}}\right) W^{O} \ \text { where head }{\mathrm{i}} &=\operatorname{Attention}\left(Q W{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right) \end{aligned}$$
$$W_{i}^{Q} \in \mathbb{R}^{d_{\text { model }} \times d_{k}}, W_{i}^{K} \in \mathbb{R}^{d_{\text { model }} \times d_{k}}, W_{i}^{V} \in \mathbb{R}^{d_{\text { model }} \times d_{v}}$$
论文中每一层有 h=8 个 attention
输入的向量大小为 512,为了保持大小相同,每个 attention 中的 $$d_k=d_v=d_{model}/h=64$$
从原理上来看,multi-head 相当于在计算次数不变的情况下,将整个 attention 空间拆成多个 attention 子空间,引入了跟多的非线性从而增强模型的表达能力。
论文中一共使用了三种 multi-head attention
encoder-decoder attention:query 来自前一个 decoder 层的输出,keys,values 来自最后一个 encoder 输出。- 其意义是: decoder 的每个位置去查询它与 encoder 的哪些位置相关,并用 encoder 的这些位置的 value 来表示。
encoder self-attention:query,key,value 都来自前一层 encoder 的输出。这允许 encoder 的每个位置关注 encoder 前一层的所有位置。decoder masked self-attention:query,key,value 都来自前一层 decoder 的输出。这允许 decoder 的每个位置关注 encoder 前一层的、在该位置之前的所有位置。第一种 QVV 模式,后面两种 VVV 模式
Multi-Head Attention
https://blog.xiang578.com/post/logseq/Multi-Head Attention.html